

如果科学是寻找真理的一种客观手段,那它也同样要求人类的判断。假如说你是一位怀揣这样一个假说的心理学家:人们其实明白他们对被污名化群体带有一种潜意识的偏见;如果你问他们,他们将会承认这一点。那可能看起来是一个颇为直接的观点——这一观点非对非错。但测试它的方式却并不显而易见。首先,什么是消极的刻板印象?你所讨论的被污名化群体是指哪一类?你如何测量人们在什么程度上能够意识到他们的隐性态度?你将如何测量人们在何种程度上愿意自我披露?
这些问题将以许多种不同的方式得到回答:而反过来,又可能导致大量不同的发现。一个新的众包实验——涉及到超过24个国家地区的15000名被试和200名研究人员——证实了这一点。不同的研究项目以自己的方式来测试同一系列的研究问题时,往往会得到差异化的、有时甚至是对立的结果。
这个众包项目戏剧性地展示了被广泛讨论的可重复性危机中的观点。研究者们在设计他们的研究时做出的主观决策,能够对观察的结果产生巨大的影响。不论是通过“P值篡改(p-hacking)*”,或者是他们漫步在“小径分叉的花园”时所做出的选择,研究者都可能有意无意地将结果引向一种特定的结论。
*译者注:P值篡改:科研人员通过不断地改变统计方法以使p值<0.05,导致结果的假阳性和实验的不可重复性。
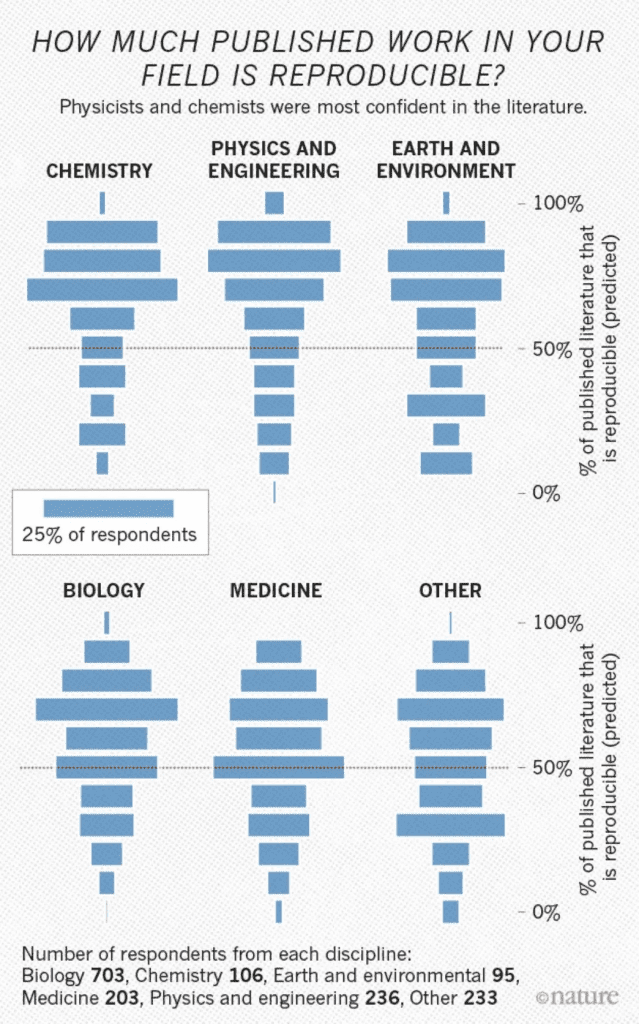
2016年Nature的一篇论文探讨了学术界发表结论的可重复性问题。来自各界的1500名科学家回答了他们对于所在学科存在何种程度的可重复性危机, 其中物理和化学科学家对自家文献的可重复最自信。
这篇新论文的主要作者,新加坡国际商学院(INSEAD)的心理学家艾瑞克·乌拉曼(Eric Uhlmann),曾将将矛头指向一项研究。在这项研究中,29个研究团队收到了同样一组数据集,而这些团队要用这个数据集回答一个简单的研究问题:“相对较浅肤色运动员而言,足球裁判员是否会给深肤色的运动员更多的红牌?”尽管分析的数据是完全一样的,但是没有哪两支团队能给出相同的答案。然而,这些团队的发现确实都指向了同一个方向。
红牌研究显示了数据分析的决策是怎样影响到结果的,但乌尔曼也担心其他的决策也会卷入研究设计中。因此他发起了最近的这项研究。这项研究规模更庞大,也更野心勃勃,未来会在《心理学公报》(The Psychological Bulletin)(数据和材料都在网上公开)上发表。这一项目从五种假说开始。这五种假说都已得到实验性检验,但实验的结果仍未公布。
除了像上述足球运动员所体现的潜在联系的假说之外,这些假说还包括:人们如何回应激进的谈判策略,或者什么样的因素会让人们更愿意接受运动员使用兴奋剂。乌尔曼和他的同事向很多研究团队抛出了同样一个问题,但并不告诉他们有关最原始的那项研究的信息,或者那些研究发现了什么。
随后,这些团队分别设计了各自的实验,以检验一些共同因素作用下的假设。这些研究必须在线上进行,从共享的被试数据库里随机地抽取出参与者。每一项研究设计都操作了两次:第一次的被试来自亚马逊公司的Mechanical Turk(译者注:亚马逊旗下的劳务众包平台),第二次则是全新的、从一个叫Pure Profile的调查公司里找到的一群被试。
研究表明,这些团队在设计实验时中会出现巨大差异。例如,第一个假说是关于人们是否能够意识到他们会存在内隐偏见(unconscious bias)。一个团队仅仅要求被试按他们对如下叙述的赞同程度评级:“不管我对社会公平抱有怎样的外在信念(也就是,有意识地),我相信我对被污名化的社会群体成员会自动地(无意识地)持有消极联想。”根据这一回答,他们得出该假设是错误的:人们并不报告潜在的消极成见的意识。
对于这个假说,另一个团队则是这样测试的:他们询问被试对一个政治党派的自我认同感,然后让他们按对假定的对立党派成员的感觉做一个评级。以这种方法,他们发现了人们很愿意报告他们自己的消极成见。而第三个团队给被试展示了白皮肤、黑皮肤或者超重肥胖的(也有小猫小狗的)男男女女的照片,然后让他们按自己对这些人直接的直觉反应评级。他们的结果也展示了人们确实承认对被污名化群体的成员持有消极成见。
这项研究结束时,有七个团队发现了支持这一假说的证据,而有六个团队则发现了反对证据。综合一切考虑,这些数据并不能支持“人们能意识到、且报告他们自己的潜在成见”的观点。但是,如果你看到的只是一个团队设计的结果,那很容易就会得到一个不同的结论。
这项研究发现,五种假说中有四种假说都出现了一种相似的模式:不同的研究团队在相反的方向上产生了统计学显著效应。哪怕一个研究问题的答案所指方向一致,影响的效应大小却相差甚远。在13个研究团队中,有11个团队得出的数据能够清晰地支持“极端的提议让人们更加不相信谈判”的假说。然而,在剩下的两个团队中发现的统计效应只隐约指向这种观点。一些团队发现极端的提议对信任有很大的影响,而其他团队发现这些因素影响甚微。
示例一:“当直接问到:人们是否会自我袒露一种隐匿的、对污名化社会群体成员的不由自主的消极联想?”
示例二:“比起在一开始先做出缓和的提议的谈判者,在一开始先做出极端化的提议的谈判者,会让人对其更加信任还是更不信任,或者都一样呢?”
示例三:“哪种效果会不顾物质/经济的需求而持续地作用对那些群体的道德判断:有利的还是有害的,或者没有任何影响?”
示例四:“人们反对兴奋剂在体育运动中的使用的原因,部分出自于他们‘违背了规则’……”
示例五:“功利主义还是伦理方向的义务论更能联系到个人的福祉?”
——柯亨的d效果范围,95%的置信区间
安娜·德勒柏(Anna Dreber)认为,这个故事告诉我们,单单一项研究能告诉我们的无足轻重。她是斯德哥尔摩经济学院(the Stockholm School of Economics )的经济学家,也是该项目的作者之一。“我们作为研究者,必须对我们怎么说话格外小心,你不该说,‘我已经检验了这个假说’,你必须说,‘我用一种特定的方式检验了它’,它对其他情况是否具有普遍性取决于更多的研究结果。”
这个问题,以及披露这个问题的办法,并不是社会心理学所独有的。与此相似的是,近日一个项目让70个团队用同一个功能性磁共振图像的数据集合来检验9种假设。没有两支团队使用了完全一样的方法,而不出意料的是,他们的结果各种各样。
如果只通过这些项目的结果来判断,那么我们也许可以合理地推测出科学文献如同一片结果对立的密林(如果对于同一个问题,不同的研究团队总能得到不同的答案,那么期刊中应该满是矛盾)。然而,事实与此相反。科学期刊中到处都是确证假设结果成立的研究,而那些零结果就不幸成为了“文件抽屉”问题*(file-drawer problem)的一部分。想想上述关于内隐偏见的假说的结论:一半的团队发现有利证据,一半的团队发现反对证据。如果这项研究真的以出版为目标,那么前者将在正式论文中找到落脚点,余下的将被掩盖并遗忘。
*译者注:“文件抽屉”问题(file-drawer problem):在科研出版界,人们倾向于筛选性地发表更积极、显著的结果。
乌尔曼及其同事的证明,提示了假设应该在多样且透明的方式中得到检验。“我们需要做更多的研究,试着以不同的方式看待同一个问题。”来自牛津大学的心理学家多乐丝·毕肖普(Dorothy Bishop)说道。那样的话,你可以“在你上蹿下跳、跳舞庆祝之前,真正地阐明它有多么可靠”。
结果当然是论证了谦卑审慎的重要性,乌尔曼说。“我们必须谨慎地对待我们在文章中、我们的大学在公开出版物中、我们在媒体采访中所说的内容,我们需要严谨地对待我们的主张。”各种名利奖赏刺激我们推出重大论点,但好的科学或许意味着放慢速度,更加谨慎地实践。
放慢速度也是伦敦大学学院心理学家乌塔·费瑞斯(Uta Frith),在一篇最近发表于《认知科学趋势》( Trends in Cognitive Sciences)的论文里所提出的。费瑞斯写道,“目前的‘发表或发霉’(publish or perish)的文化,对科学家和科学自身具有腐蚀性的影响。”多发论文,而不是努力发表高质量的论文,这给研究者带来压力的同时,也欺骗了科学,她说。“快的科学让我们走小路、抄近道,也的确会导致可重复性危机。”她写道。那么她的建议是什么呢?“慢科学。”它致力于“科学的更大目标”——即作为一种寻找真理的方式。她说,对研究者而言,促进“慢科学”的方法,就是从特级葡萄园的葡萄栽培实践中寻找启发——他们为了维持葡萄酒的最优质量,而想尽办法限制其产量。
毕肖普也提出类似的建议,科学家要限制他们的产出,“为了发展一种理论,你需要大量的观察,而我认为我们常常观察得很少,”她说,“然后我们在不成熟的时候就进行理论建构。但如果我们能够更广泛,更全面地去探索那些得到观察的情况,那我们的理论建构也会更优质一些。”如果说,这项关于五种假说的研究教会了我们什么,那就是:科学是一个过程,而且是一个漫长的过程。
翻译:兵书;校对:曹安洁












 沪公网安备31011202020814号
沪公网安备31011202020814号
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
评论