

在过去十年,人工智能(特别是深度学习)取得了显著成效。当Siri读懂你说的话、脸书认出了你的表亲、谷歌地图为你重新规划路线时,都大概率涉及到了深度学习系统。
鲜为人知的是,这些模型正消耗着惊人的成本,不仅体现在真金白银上,也体现在能源消耗上。照目前的迹象来看,人工智能只会给气候危机火上浇油。可相比之下,我们的大脑(功耗小于40瓦)可就高效多了。如果我们把基于神经科学的技术应用到人工智能中,那么用于计算的能耗将有可能大大降低,从而减少温室气体排放。这篇博文旨在解释到底是什么导致了人工智能过大的能源消耗,以及如何用基于大脑(工作原理)的技术解决这种过高的能源成本问题。
为什么人工智能如此耗能?
首先,我们有必要简单了解一下深度学习模型的工作原理。深度学习模型的“智能”之处和你的大脑并不一样。它们不以结构化*的方式学习信息。与你不同,它们不懂什么是因果关系*、上下文*或类比*。深度学习模型是用“蛮力”的统计技术*。
例如,你要是想训练一个深度学习模型来辨认一张猫的照片,你需要向它展示上千张由人类标记过的猫的图像。该模型并不知道猫比狗更有可能爬树、玩羽毛*。因此除非我们拿包含树和羽毛的猫的图像来训练它,否则它不会知道这些物体的存在可以帮助对猫的识别。而为了做出这些推断,我们需要用所有可能的物体组合图片对模型进行“蛮力”训练。
*译者注:结构化:作者此处想表达的也许是深度学习模型不像人一样建立各种概念,而且知道这些概念之间的关系(因果关系、先后关系、相似/相邻关系)。但深度学习模型确实是以结构化的方式来学习信息的——模型在加入归纳偏置后具有某种等变特性,能够处理特定结构的数据(图像、时间序列、图结构的数据等)。因此此处表述不准确。
因果关系:诚如作者所言,机器学习模型一直为人诟病之处便是其仅习得关联,而非因果。但近期有研究已经开始探索似乎在大语言模型中涌现的因果关系,如Can Large Language Models Distinguish Cause from Effect?等。亦有相当多研究者开始关注因果表示学习这一新兴领域。
上下文:事实上,上下文学习对自GPT3之后的大语言模型来说并不是什么难事,并诞生了in-context learning这样一个专门研究这一能力的子领域。近期包括Can language models learn from explanations in context?,Emergent Abilities of Large Language Models,What learning algorithm is in-context learning? Investigations with linear models在内的多项研究进一步探索了其机制。
类比:近期已有研究表明,类比推理能力在大语言模型中涌现,如Emergent Analogical Reasoning in Large Language Models所述。
深度学习模型是用“蛮力”的统计技术:原文如此,不一定正确。
该模型并不知道猫比狗更有可能爬树、玩羽毛:值得注意的是,作者此处所描述的深度学习系统更多聚焦于单任务系统。但事实上,早在几年前,多任务学习(multitask learning)便已经成为十分流行的范式,并且目前最引人瞩目的一些深度学习系统更开始强调一个模型适用于多种任务,如DeepMind的Gato,Google的PaLM等。
这些运用“蛮力”的统计模型所产生的巨大能源需求是由于以下几个特点:
需要成百万上千万的训练样本。在猫的例子中,训练好一个模型需要正面、背面、侧面、不同品种、不同颜色、不同阴影以及不同姿势的猫的图片。一只猫的形态有无数种可能性,因此为了成功识别一只猫,模型必须在众多版本的猫(的图片)上进行训练。
需要很多的训练周期。从错误中学习是训练模型这一过程中的一部分。如果模型错误地把猫标记为浣熊,该模型需要重新调整它的参数以将图像分类为猫*,再重新进行训练。它从一次次错误中慢慢学习,这也需要一遍遍的训练。
当遇到新的信息时得从头训练。如果这个模型现在要去识别它从未见过的卡通猫,我们得将蓝色卡通猫和红色卡通猫添加到训练集中,从头对它进行训练。该模型无法循序渐进地学习*。
需要很多的权重和乘法。一个典型的神经网络包含很多由矩阵表示的连接或权重,其中一个或多个矩阵构成一层。为了计算一个输出,神经网络的后续层需要执行大量的矩阵乘法,直至最后得到一个结果。事实上,计算单个层的输出就需要数百万次浮点运算,而一个典型的神经网络可能包含数十到数百层,这使得其计算极其耗能。
*译者注:猫:原文为浣熊,此处应指猫。
该模型无法循序渐进地学习:原文如此。但这一说法并不准确,机器学习中的增量式学习(incremental learning)或与其高度相关的在线/持续学习(online/continual learning)的目标便是循序渐进地学习,并期望最终能够建模从未见过的数据(分布外泛化),甚至识别从未见过的物体(零样本推断)。
人工智能会消耗多少能源?
一篇来自麻萨诸塞大学阿默斯特分校的论文称,“训练一个人工智能模型可以产生的碳排放量,相当于五辆轿车在整个使用期中的排放量。”然而,这项分析仅仅只针对一次训练而已。当模型经过反复训练而改进时,其能耗会激增。许多大公司每天都在训练成千上万个这样的模型,它们对此问题都十分重视。Meta就是这样一个公司,其最近发表的论文探索了人工智能对环境的影响、研究了解决问题的方法、并呼吁有所行动。
当前最新的语言模型包含了数以亿计乃至万亿计的权重。其中一个流行的模型GPT-3就有1750亿个机器学习参数。该模型在NVIDIA V100 GPU上训练,虽然研究人员尚未披露该模型的能源使用情况,但通过研究人员的计算,如果使用A100系统则需使用1024个GPU、耗时34天、花费460万美元来训练此模型,也就是936兆瓦时。此外,谷歌AI刚刚公布了具有5400亿个参数的模型PaLM(Pathways Language Model)。随着模型变得越来越大以应对愈加复杂的任务,它们对服务器的需求呈指数增长。
—
https://www.economist.com/technology-quarterly/2020/06/11/the-cost-of-training-machines-is-becoming-a-problem
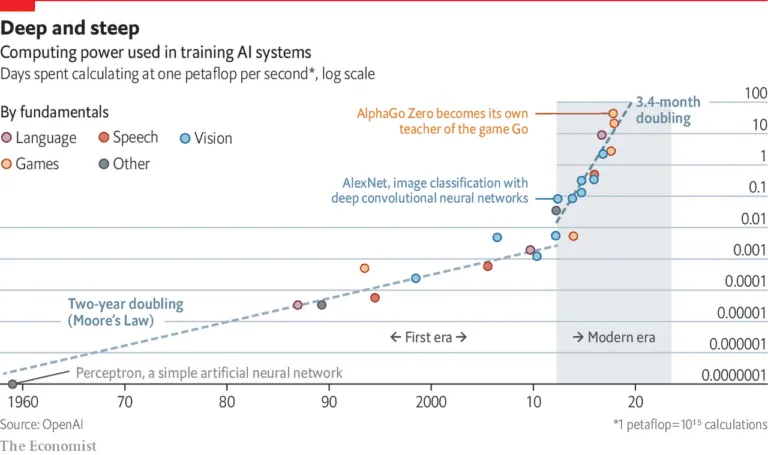
自2012年以来,训练这些人工智能系统所需的计算资源每3.4个月就会翻一番。一位商业合作伙伴告诉我们,他们的深度学习模型足以为整座城市供电。这种能源使用的上升与许多组织声称在未来十年内实现“碳中和”的目标背道而驰。
我们该如何减少人工智能的碳足印?
为了解决这个具有挑战性的问题,我们的建议是:向大脑学习。人脑是一个真正的智能系统最好的例子,然而它只消耗很少的能量(基本上与点亮一盏灯泡的能量相同)。与深度学习的低效率相比,人脑的效率极其显著。
那么人脑是如何高效运作的呢?我们根植于神经科学的研究指出了一条让人工智能更加高效的路线。以下是大脑在不过多使用能量的情况下却能出色地处理数据的背后的几个原因:
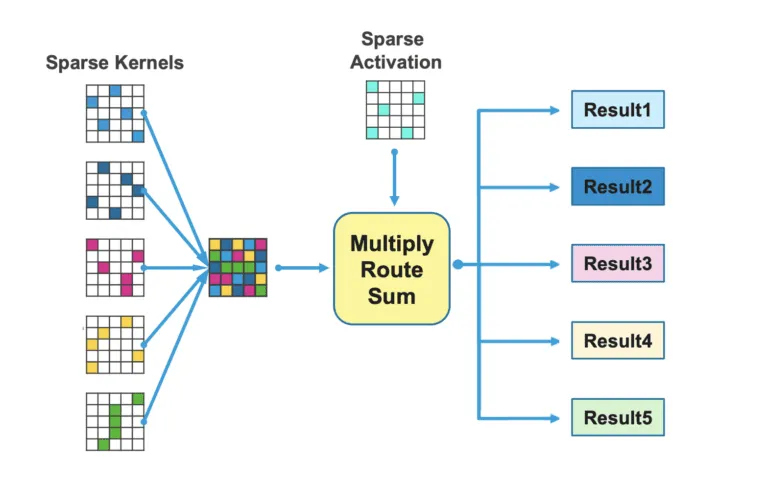
1 / 稀疏性
大脑中的信息编码是非常稀疏的,这就像在一长串主要为零的字符串中零星掺杂着一些非零值。这与计算机的表示方法不同,后者通常是密集的。由于稀疏表征有很多零元素,因此它们在和其他数字相乘时可以被消掉而只剩下非零值。而大脑中的表征非常稀疏,其中多达98%的数字都是零。
如果我们可以通过具有类似稀疏度的人工智能系统表示信息,那么就可以消除大量的计算。我们已经证明,在深度学习的推断任务(inference tasks,例如在视觉系统中识别猫)中使用稀疏表征可以将功率性能在不损失任何准确度的前提下提高到三至一百倍以上(具体取决于网络、硬件平台和数据类型)。
深入了解:将稀疏性应用于机器学习
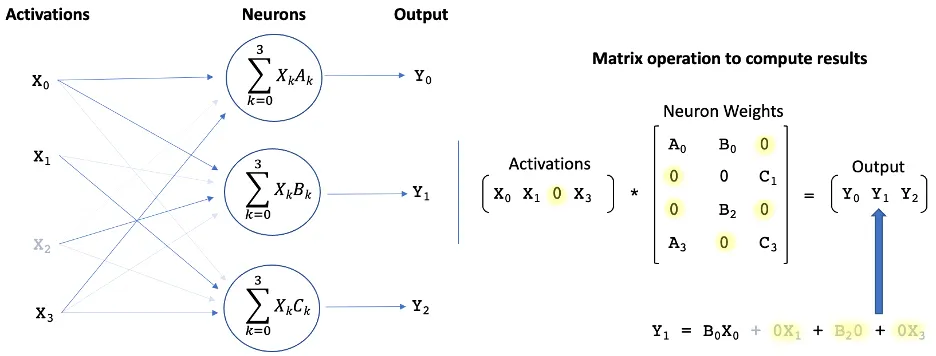
将大脑的稀疏性转移到深度神经网络(DNN)有两个关键点:激活稀疏性(activation sparsity)和权重稀疏性(weight sparsity)。稀疏网络可以限制其神经元的活动(激活稀疏性)和连接(权重稀疏性),从而显著降低模型的大小和计算复杂度。
—
https://arxiv.org/abs/2112.13896
2 / 结构化数据
你的大脑通过感官信息流和不断移动来对这个世界进行建模。这些模型具有三维结构,所以你的大脑能理解猫的左视图和右视图,而不必单独去学习它们。这些模型基于我们所谓的“参照系”,它让学习变得结构化,使我们能够建立包含各种对象之间关系的模型。
我们可以纳入猫和大树、羽毛都有关联的概念,而不必去看数百万只猫与大树的实例。与深度学习相比,使用参照系构建模型所需的样本要少得多。只需猫的几个视图,模型就能通过变换数据来理解猫的其他视图,而无需专门针对这些视图进行训练。这种方法可以将训练集减小好几个数量级。
深入了解:通过参照系来结构化学习
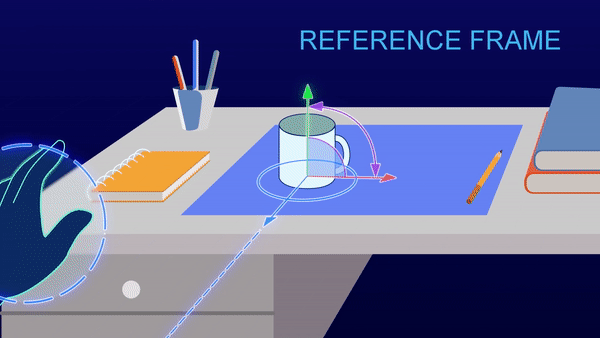
参照系就像地图上的网格或坐标轴。你所知的每一个事实都与参照系中的某个位置一一配对,你的大脑则在参照系中不断移动来回忆储存在不同位置的事实。这使你能够在脑海中移动、旋转和改变事物。你可以在参照系里根据蓝色和现实中猫的样子来想象一只蓝色卡通猫长什么样,而不需要看一百张从各个角度拍的蓝色卡通猫图片。
—
https://www.youtube.com/watch?v=LaAYuygr7_8&ab_channel=Numenta
3 / 持续学习
你的大脑在学习新事物的同时不会忘却之前所学的东西。当你首次见到一种动物时(比方说土狼),你的大脑不需要重新学习一切关于哺乳动物的知识。大脑把一个针对土狼的参照系添加到记忆中,然后标注其与其他参照系(例如狗)的异同,并共享那些相通的子结构(例如尾巴和耳朵)。这种递增式的学习只需要很少的能量。
深入了解:用活跃树突(active dendrites)来进行多任务和持续学习
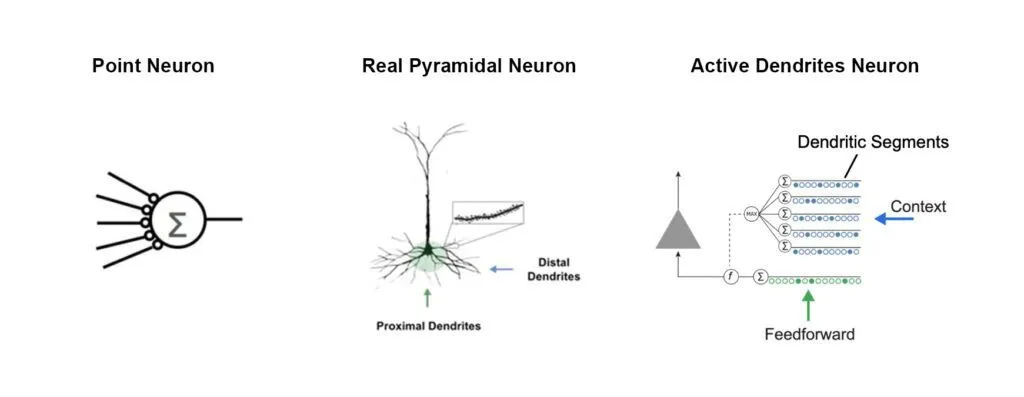
生物神经元有两种树突:远端(distal)和近端(proximal)。如今我们所见的人工神经元只模拟了近端的树突。我们已经证明,通过把远端树突合并到神经元模型,神经网络可以在不忘却旧知识的前提下学习新知识,从而避免重新学习的需要。
—https://www.frontiersin.org/articles/10.3389/fnbot.2022.846219/full
4 / 优化的硬件
如今的半导体架构都是为深度学习优化的,这其中,神经网络密集而不具备结构化学习的能力*。但我们如果想创造更可持续的人工智能,就需要让硬件也能包含上述三个属性:稀疏性、参照系和持续学习。我们已经创造了一些支持稀疏性的技术。这些技术将稀疏表示映射到密集的计算环境中,从而提高推断和训练性能。长远来看,我们不难想象这些基于大脑原则优化的架构将有潜力提供更多的性能提升。
*译者注:原文如此,不代表正确。
深入了解:互补稀疏性
在2021年,我们引入了互补稀疏性。这是一种利用稀疏权重和稀疏激活函数来提升性能的技术,从而实现更节能的硬件。我们最近用互补稀疏性在FPGA上运行推断任务,并在吞吐量和能源效率上取得了近百倍的进步。
—
https://arxiv.org/abs/2112.13896
迈向更可持续的未来
继续构建更大型、计算量更密集的深度学习网络不是通向创造智能机器的可持续途径。Numenta(原作者)认同的是通过一种基于大脑的方法来构建高效且可持续的人工智能。我们必须开发更聪明的、而不是工作更勤快的人工智能。
更少的计算量、更少的训练样本、更少的训练次数与优化的硬件相结合,可以显着改善能源使用。如果我们的计算量减少十倍、训练样本减少十倍、训练次数减少十倍、硬件效率提高十倍,那么系统的整体效率将提高一万倍。
短期内,Numenta希望能大幅降低推断(inference)中的能耗。Numenta的中期目标是将这些技术应用到训练中,并随着训练次数的减少,预计可以节省更多的能源。从长远来看,随着硬件的逐渐增强,Numenta看到了将性能改进上千倍的潜力。
从大脑中提取抽象的原理然后应用到如今的深度学习架构中会把我们推向可持续的人工智能。如果读者想详细了解Numenta在创建节能的人工智能方面的工作,请查看原文以了解更多。
后记
lemon:最开始知道Numenta这家公司是因为读了Jeff Hawkins的On Intelligence,这本书描述了一种直截了当的接近“强人工智能”的方式——模拟人类的大脑皮层。Numenta的出发点是:既然智能可以从人类的大脑皮层中产生,那么模拟大脑皮层的算法也将获得智能。我深深地被这个想法吸引。模拟大脑皮层vs人工神经网络,到底谁更胜一筹呢?我十分期待答案揭晓的那天。
P:读原文时,我的第一感觉就是文章本身带有很强的主观色彩,尤其是在试图证明AI只是“用蛮力的统计技术”时,有相当多刻意且过时的观点。诚然,大模型的训练开销和碳排放巨大,比如原文提到的,GPT-3的训练碳排放相当于五辆小汽车的终身排放。但是,我们也必须承认从大模型中涌现出来的惊人能力。尽管这篇文章写于去年五月,当时当然还没有ChatGPT,但已经有不少研究发现了在大语言模型中涌现的多种能力,比如我们注释的推理和类比等等。不过,我个人也十分认同Bengio、Botvinick、LeCun等学者去年提出的NeuroAI的核心观点,即从硬件和软件层面向人脑的架构学习,进一步推进AI的发展。总而言之,我们希望读者了解当前已经取得的进展,以及在把AI的边界继续向前推进时所能获得的潜在收益。
Sixin:这是一家旨在将神经科学原理融入人工智能产品的公司。为了宣传自己,开头部分可能会出现一些稻草人谬误,夸大了深度学习的一些问题。正如译者与校审者在注释中所补充的,随着研究者们不懈努力,这些问题其实已经部分甚至全部得到了解决,读者可以按图索骥。不过,本文所提出的参考人脑“稀疏性、结构化、学习持续性”三种特点来降低人工智能产品能耗的想法还是很有启发性的,读者可以去粗取精。
作者:Charmaine Lai, Subutai Ahmad, Donna Dubinsky & Christy Maver | 译者:lemon | 审校:P | 编辑:sixin、M.W. | 封面:Valeriy Zarytovskiy | 排版:光影 | 原文:https://www.numenta.com/blog/2022/05/24/ai-is-harming-our-planet/















 沪公网安备31011202020814号
沪公网安备31011202020814号
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
评论